 뉴스레터
뉴스레터








AI가 시험을 통과하고 코드를 짜고 논문을 요약하는 시대, 이제 남은 질문은 하나다. "AI는 창의적인가?"
최근 AI가 평균적인 인간보다 창의적이라는 대규모 연구 결과가 나왔다. 그러나 창의성이 높은 인간 집단과의 격차는 여전히 뚜렷해, AI가 인간의 창의 노동을 대체할 것이라는 우려는 아직 이르다는 결론도 함께 제시됐다.
캐나다 몬트리올 대학교 인지컴퓨팅 연구소의 앙투안 벨마르-페팽(Antoine Bellemare-Pepin)교수 연구팀은 GPT-4를 비롯한 최신 대형언어모델(LLM) 여러 종을 대상으로 10만 명의 참가자와 동일한 창의성 검사를 실시해 비교·분석한 결과를 국제학술지 사이언티픽 리포츠(Scientific Reports)에 발표했다.

10만 명의 인간 vs. 최신 AI
연구팀은 GPT-4, GeminiPro, Claude3 등 총 9종의 주요 대형언어모델(LLM)을 10만 명의 인간 참가자와 동일한 기준으로 비교했다. 연구팀이 채택한 도구는 '확산적 연상 과제(Divergent Association Task, 이하 DAT)'다. 참가자에게 의미적으로 최대한 서로 다른 단어 10개를 나열하게 하고, 단어 간 의미 거리를 수치화하는 방식이다. 창의적 사고의 핵심인 '연상적 사고력' 즉, 멀리 떨어진 개념들을 연결하는 능력을 측정하기 위해 설계된 검사로 자연어 생산이라는 공통 과제를 통해 인간과 AI를 동등하게 비교할 수 있다는 장점이 있다.
인간 참가자 10만 명은 성별과 연령대가 균형 있게 구성됐으며, 미국·영국·캐나다·호주·뉴질랜드 등 영어권 국가 출신이다. 각 모델은 동일한 프롬프트로 500회씩 응답을 생성해 통계적 안정성을 확보했다.
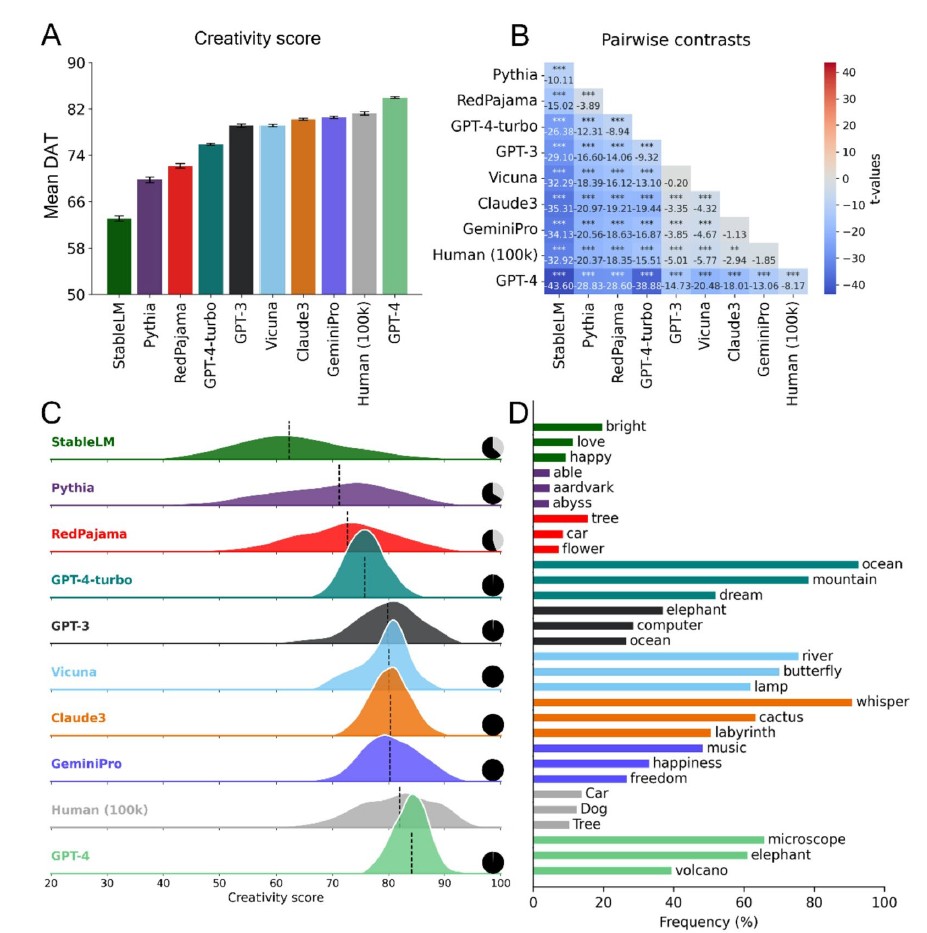
GPT-4, 인간 평균 넘었다…GPT-4-turbo는 오히려 퇴보
가장 주목할 결과는 GPT-4의 창의성 점수가 인간 평균을 통계적으로 유의미한 수준으로 넘어섰다는 점이다. GeminiPro는 인간 평균과 통계적으로 구분되지 않는 수준에 도달한 반면 GPT-4의 후속 버전인 GPT-4-turbo는 성능이 오히려 전작보다 뚜렷하게 떨어졌다. 모델의 크기가 곧 창의성을 보장하지 않는다는 의미다. 연구팀은 이를 "효율성·비용 최적화 과정에서 언어 다양성이 희생됐을 가능성"으로 해석했다.
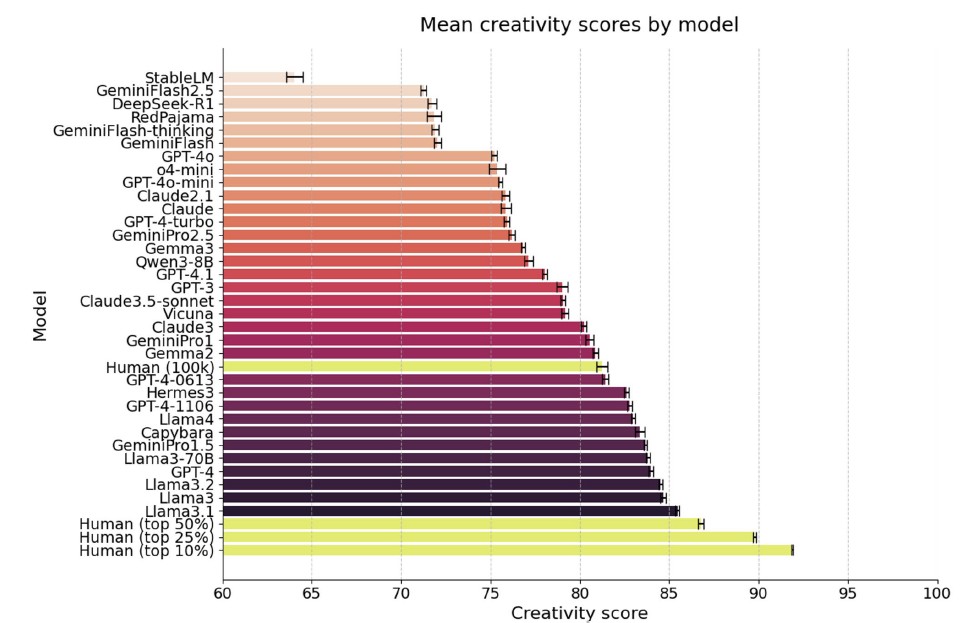
그러나 결정적인 한계도 확인됐다. 2023년 1월부터 2025년 6월 사이에 출시된 광범위한 LLM을 추가 분석한 결과, 어떤 모델도 인간 상위 50%의 평균 DAT 점수를 넘어서지 못했다. 상위 25%, 상위 10% 인간 집단과의 격차는 더욱 컸다. 연구팀은 "AI가 빠르게 발전하고 있음에도, 최고 수준의 인간 창의성과의 격차는 지속되고 있다"고 강조했다.
다양성 설정값 높이면 창의성도 올라간다…프롬프트 설계가 관건
연구팀은 LLM의 창의성이 고정된 값이 아니라 설정에 따라 조율 가능하다는 사실도 입증했다. 핵심 변수는 다양성 설정값(temperature)이다. 이것은 AI 모델이 다음 단어를 고를 때 얼마나 다양한 선택지를 허용할지를 조절하는 수치로 설정값이 높을수록 AI의 단어 선택이 더 다양하고 예측하기 어려워진다. 즉, 값이 낮으면 모델은 통계적으로 가장 확률 높은 단어만 반복해서 고르고, 값이 높으면 평소에는 잘 선택되지 않던 단어들도 후보에 올라온다.
실제로 연구팀이 GPT-4의 이 설정값을 낮음(0.5)·중간(1.0)·높음(1.5)으로 달리 조정한 결과 설정값이 높아질수록 DAT 점수가 유의미하게 상승했다. 낮은 설정에서는 'microscope'나 'elephant' 같은 몇 가지 단어가 응답의 대부분을 차지했고, 반면 값이 올라갈수록 이런 반복이 줄고 단어 선택의 폭이 넓어졌다. 최고 설정 조건에서는 인간 참가자의 72%를 웃도는 창의성 점수가 산출됐다.
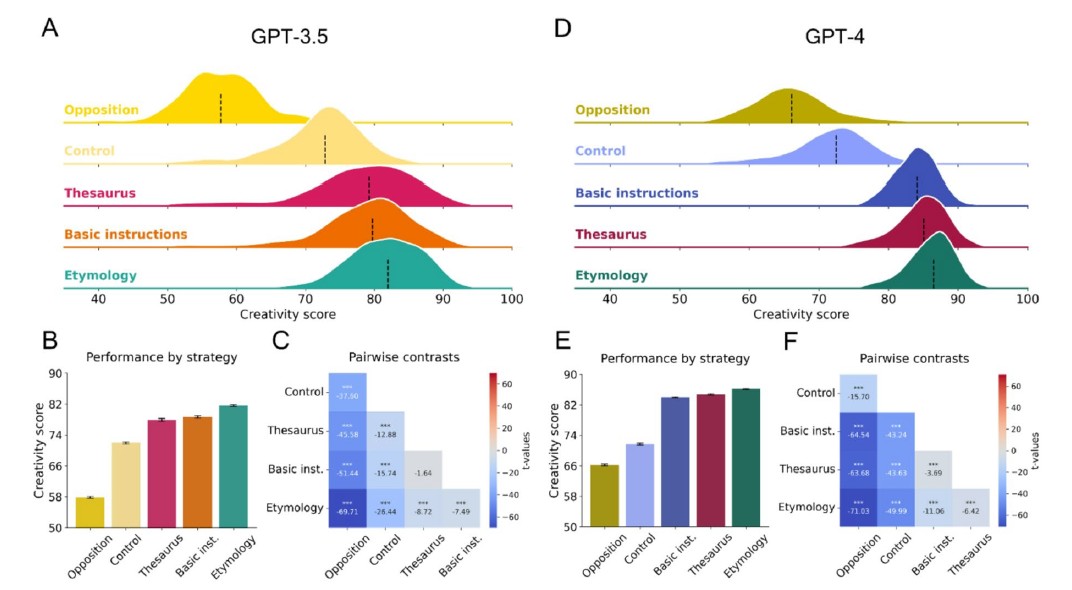
프롬프트 전략도 창의성 점수를 갈랐다. 언어적 기원을 달리하도록 유도하는 '어원 다양성(etymology) 전략'을 지시했을 때, GPT-3.5와 GPT-4 모두 기본 지시 조건보다 높은 점수를 기록했다. 반면 반의어를 나열하도록 지시한 경우에는 점수가 유의미하게 낮아졌다. 'light'와 'darkness'처럼 반의어 쌍은 의미적으로 오히려 가깝기 때문이다. 동일한 모델도 어떻게 묻느냐에 따라 창의적 산출물의 질이 크게 달라진다는 것이다.
하이쿠·시놉시스·플래시 픽션…창작 글쓰기에서도 인간이 우세
창작 글쓰기에서도 인간은 LLM을 앞섰다. GPT-4가 GPT-3.5보다 일관되게 높은 점수를 냈지만, 인간 작가들의 글은 어떤 LLM도 따라가지 못했다.
차이는 숫자만의 문제가 아니었다. 연구팀이 텍스트를 시각화한 결과 인간이 쓴 글과 AI가 쓴 글은 의미 공간에서 아예 다른 영역에 자리 잡았다. 인간의 글과 AI의 글은 내용과 구조 자체가 다른 클러스터를 형성하는 차이를 보였는데. 연구팀은 AI가 생성한 스토리는 전문 작가의 글과 비교했을 때 창의성 기준을 통과하는 빈도가 3~10배 낮은 결과와 무관하지 않다고 설명했다.
흥미로운 점은 다양성 설정값의 효과가 글의 형식에 따라 달랐다는 것이다. 시놉시스나 플래시 픽션처럼 비교적 자유로운 형식에서는 설정값을 높일수록 창의성 점수도 올랐다. 반면 5·7·5 음절이라는 엄격한 규칙을 따르는 하이쿠에서는 같은 효과가 나타나지 않았다. 형식의 제약이 강할수록 설정값 조정만으로는 창의성을 끌어올리기 어렵다는 것이다.
"AI가 작가를 대체한다"…아직은 시기상조
연구팀은 일부 상용 모델의 구조와 규모 등 세부 사양이 공개되지 않아 성능 결정 요인을 특정하기 어렵고, 모델의 훈련 데이터에 DAT 자체가 포함됐을 가능성도 배제할 수 없다고 연구의 한계를 설명했다. 또한 이번 연구의 창의성 측정은 언어적·의미적 발산에 집중돼 있으며, 수렴적 사고나 유용성·참신성을 아우르는 더 넓은 창의성 개념은 다루지 못한다.
그럼에도 제르비 교수는 "AI가 인간의 창의 노동을 대체할 것이라는 우려는 시기상조"라며, "AI와 인간이 경쟁이 아닌 창의적 협업의 파트너로 작동할 가능성에 주목해야 할 시점"이라고 강조했다. 연구팀은 이번에 구축한 평가 프레임워크와 분석 코드를 오픈소스로 공개했다. 빠르게 진화하는 LLM 생태계에서 창의성 평가가 하나의 표준 벤치마크로 자리 잡을 수 있도록 지속적으로 업데이트할 계획이다.
- 김현정 리포터
- vegastar0707@gmail.com
- 저작권자 2026-04-09 ⓒ ScienceTimes
관련기사










