 뉴스레터
뉴스레터








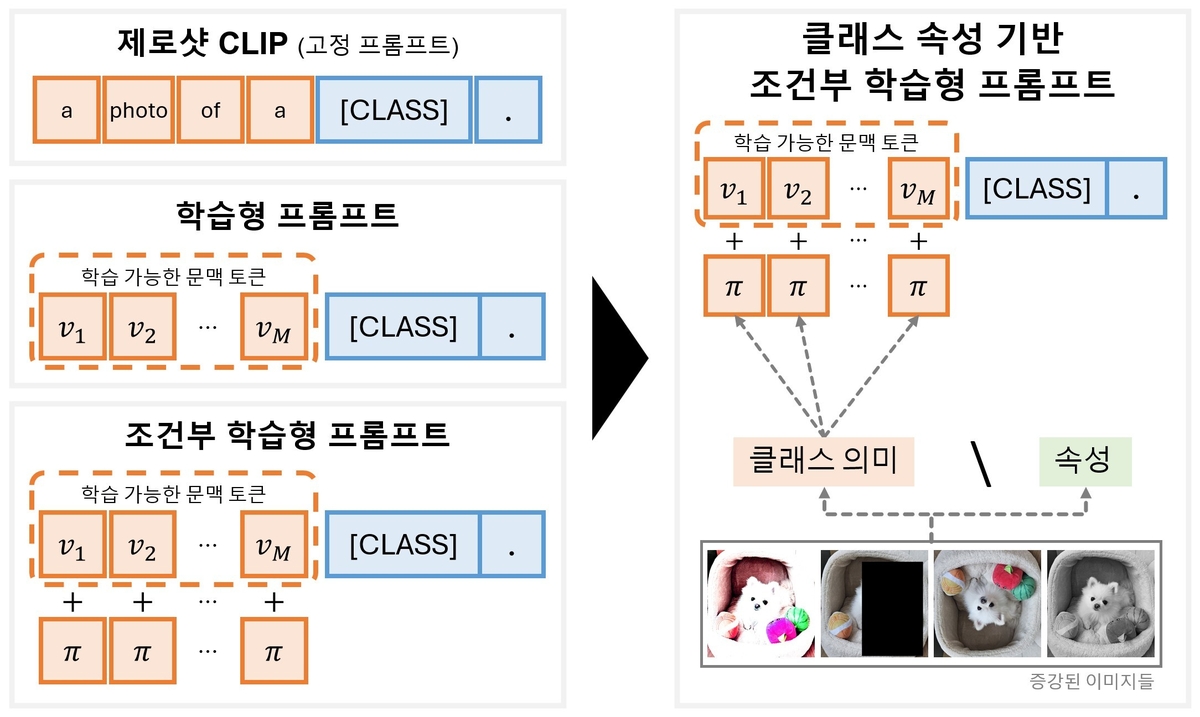
한국에너지공과대학교(KENTECH·켄텍)는 비전-언어 모델(Vision-Language Model)이 이미지의 본질적인 속성만 학습하도록 설계한 프롬프트 학습 기법을 개발했다고 13일 밝혔다.
클립(CLIP) 등 기존 비전-언어 모델은 이미지와 텍스트를 결합해 사물의 의미를 이해하지만, 세밀한 속성 구분이 필요한 상황에서는 한계가 있어 시각적 왜곡이 발생하기도 한다.
이석주 교수와 김가현·김소희 연구원이 참여한 연구팀은 이 문제를 해결하기 위해 '델타 메타 토큰(Delta Meta Token)'을 도입했다.
이 토큰은 이미지 간의 상대적 변화를 학습해 속성 차이를 정교하게 구분하도록 돕는다.
이를 통해 모델이 데이터 변화에 덜 민감하게 반응하면서도 의미 있는 속성만 학습해 시각적으로 유사한 대상도 구별할 수 있다.
기존 방식은 '강아지'라는 클래스 정보만 학습하지만 새로운 기법은 귀, 눈, 털 등 강아지의 공통된 속성을 함께 학습함으로써 강아지의 종류가 달라져도 본질적 속성을 인식하고 도메인이 다른 데이터에서 안정적인 성능을 유지한다.
제안된 기법은 사전 학습된 CLIP 모델에 최소한의 파라미터만 추가하는 경량 구조임에도 11개 벤치마크 데이터셋에서 기존 프롬프트 학습 방법을 능가하며 높은 일반화 성능을 보였다.
새로운 클래스나 도메인이 주어져도 안정적인 인식을 유지해 자율주행·로봇 비전·산업 영상 이상 검출 등 다양한 분야에 활용될 것으로 기대된다.
이 연구는 국제 학술지 'Pattern Recognition (Elsevier)'에 지난 달 23일 온라인으로 게재됐다.
- 연합뉴스
- 저작권자 2025-11-14 ⓒ ScienceTimes
관련기사









