 뉴스레터
뉴스레터








사진이나 영상 속 3차원 공간의 깊이 등 정보를 세밀하게 추론할 수 있는 인공지능(AI) 기술이 개발됐다.
한국에너지공대(KENTECH·켄텍)는 이석주 교수 연구팀이 AI 비전 언어 모델(Vision Language Model)의 3차원 공간 추론을 가능하게 하는 경량 프롬프트(명령어) 학습 기술을 개발했다고 1일 밝혔다.
다양한 유형의 데이터를 처리하고 통합할 수 있는 AI 시스템인 멀티모달(multimodal)이나 비전 언어 모델은 이미지와 텍스트를 동시에 이해하는 AI로, 비전과 자연어 처리 융합 분야에서 널리 활용된다.
예를 들어 고양이라는 단어를 보여주면 수많은 사진 속에서 고양이를 찾아내는 방식이다.
하지만 거리와 깊이 같은 기하학적 공간 인식에는 한계가 있었다.
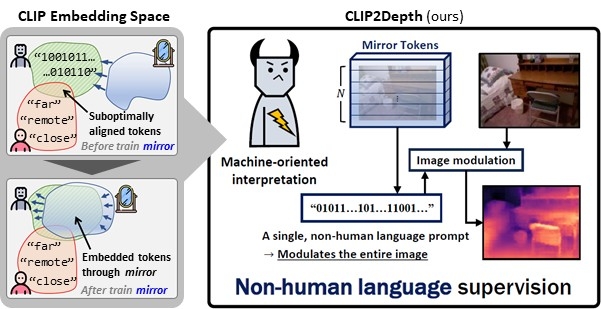
연구팀은 사람이 쓰는 언어 대신 기계가 이해하기 최적화된 새로운 표현 방식인 비인간 언어 프롬프트를 도입했다.
이를 통해 카메라에 찍힌 사진이나 영상만으로도 물체의 깊이를 정밀하게 파악할 수 있도록 했다.
이 기술은 약 110만개 학습 파라미터만으로도 3억개 이상이던 기존 대형 모델과 견줄 만한 성능을 보였다.
이번 연구는 국제 학술지 'Pattern Recognition (Elsevier, SCIE Q1, IF=7.6)'에 지난달 26일 온라인으로 게재됐다.
이 교수는 "자율주행, 로봇 비전, 증강현실 등 경량화가 필수적인 다양한 공간 컴퓨팅 분야에 활용 가능한 핵심 원천기술로 자리매김할 것"이라고 말했다.
- 연합뉴스
- 저작권자 2025-10-02 ⓒ ScienceTimes
관련기사








