 뉴스레터
뉴스레터








울산과학기술원(UNIST)은 인공지능(AI)을 탑재한 로봇 여러 대의 협력 체계가 센서 고장 등의 위기 상황에도 무너지지 않도록 유지하는 강화학습 기술을 개발했다고 30일 밝혔다.
강화학습이란 AI가 다양한 상황을 경험하며 스스로 행동전략을 익히는 학습방식이다.
그런데 다수의 AI 에이전트(주어진 환경에서 사람의 개입 없이 스스로 판단하고 결정하는 AI 시스템)를 대상으로 한 '다중 에이전트 강화학습'(MARL)에서는 하나의 에이전트에 문제가 생기더라도 나머지가 이를 보완해 전체 성능을 유지한다.
이 때문에 단일 에이전트를 무작위로 교란하는 기존 공격 방식만으로는 협력체계의 취약점을 제대로 평가하기 어렵다.
센서 고장, 날씨 변화, 의도적 해킹과 같은 현실적 위기 상황에 대한 훈련 효과도 제한적이다.
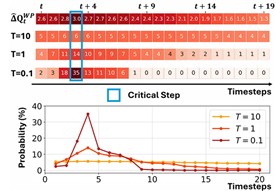
한승열 UNIST 인공지능대학원 교수팀은 이런 취약점을 해결하기 위해 다중 에이전트 협력 구조를 단계적으로 무너뜨리는 인위적 오작동 공격 전략 '울프팩 어택'(Wolfpack Attack)을 개발했다.
이 전략은 먼저 하나의 에이전트를 오작동시킨 뒤 나머지 에이전트에 연쇄적으로 문제를 일으켜 전체 협력 구조를 붕괴시키는 방식이다.
늑대가 떼를 이뤄 약한 개체를 고립시킨 뒤 이를 도우러 오는 동료 개체들을 순차적으로 제압하는 사냥 방식을 모방했다.
한 교수팀은 방어 프레임워크 'WALL'(Wolfpack-Adversarial Learning for MARL)도 함께 개발했다.
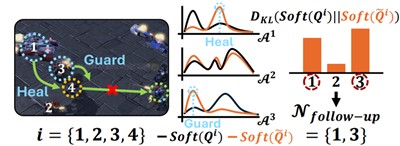
실험 결과 WALL을 통해 학습한 AI는 위치 오류나 통신 지연 같은 상황에서도 서로 부딪히지 않고 목표 지점에 도달하거나, 함께 물체를 밀고 진형을 유지하는 등 높은 적응력과 안정적인 협력 성능을 보였다.
한승열 교수는 "이번에 개발된 기술은 협력형 AI 모델의 성능을 정확히 평가하고, 위기 상황에 강한 협력 AI 모델을 만드는 데 활용될 수 있다"며 "자율 드론, 스마트 팩토리, 군사·재난 현장의 군집 로봇 산업 발전에 기여할 것"이라고 말했다.
- 연합뉴스
- 저작권자 2025-07-31 ⓒ ScienceTimes
관련기사










