 뉴스레터
뉴스레터








4차 산업혁명을 주도하고 있는 빅데이터 산업이 발전하는데 있어 최대 걸림돌은 무엇일까? 여러 의견이 있겠지만 전문가들은 대체적으로 ‘개인정보 비식별화의 성공 여부’를 꼽는다.
개인정보 비식별화란 주민등록번호나 전화번호, 또는 은행계좌처럼 특정한 개인을 나타내는 정보를 삭제하거나 대체함으로써 누가 누구인지를 알아볼 수 없도록 해당 정보를 가공하는 일련의 조치를 말한다.
개인정보가 비식별화되면 기업들은 개인정보의 오∙남용에 대한 우려 없이 수집한 개인정보들을 대상으로 빅데이터 분석을 진행할 수 있고, 개인 사용자의 동의 없이도 제 3자에게 제공할 수 있다.

이처럼 개인정보의 비식별화가 빅데이터 산업 발전의 핵심 키워드로 떠오르고 있는 상황에서 지난 12일 조선호텔에서는 개인정보 비식별화와 관련된 다양한 기술동향 및 정책들이 발표되어 관심이 모아졌다.
미래창조과학부의 후원과 정보통신진흥협회(KAIT) 주관으로 열린 이번 행사는 개인정보 비식별화 실증사업을 통해 확보한 기술 및 정보들을 현재 빅데이터 사업을 추진하고 있는 벤처기업 및 스타트업 등과 함께 공유하자는 취지로 마련됐다.
일대 일 방식의 비식별화는 재식별 가능성 존재
‘비식별 데이터의 안전한 유통을 위한 데이터실증’이란 주제로 기조강연을 한 연세대 컴퓨터과학과의 이원석 교수는 “비식별화의 성공 여부는 변환된 비식별 정보들이 얼마나 정확하고 안전한지를 기준으로 평가할 수 있다”라고 말했다.
이 교수는 “여기서 정확성이라면 비식별 정보가 원본 정보와 비교하여 얼마나 일치하는가를 평가하는 것이고, 안정성은 비식별 정보들이 다른 정보들과 결합할 때 재식별되어 노출될 가능성이 어느 정도인가를 평가하는 것”이라고 말했다.
그동안 정부는 개인정보의 유출 없이도 빅데이터를 안전하게 활용하는 방법의 하나로 ‘비식별조치 가이드라인’을 발표한 바 있다. 이 가이드라인의 발표 후 우리나라도 빅데이터 활용에 있어 한 걸음 다가섰다는 평가를 받았지만, 반면에 비식별화 기법의 안전성에 대한 논란도 끊이지 않고 있는 실정이다.
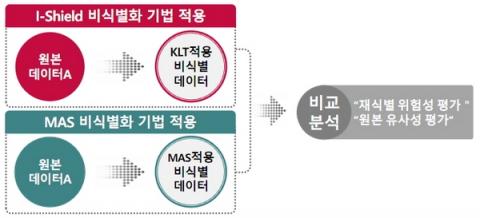
안전성에 대한 논란이 끊이지 않고 있는 이유에 대해 이 교수는 “현재 진행되고 있는 대부분의 비식별화 작업은 원래의 개인정보에 대해 비식별화된 정보가 1:1 방식으로 생성되므로, 특정 개인의 재식별 가능성을 완전히 배제할 수 없다는 단점이 있다”라고 말했다
그의 설명에 따르면 대부분의 비식별화 방법은 한 명의 개인정보에 대해 하나의 비식별 정보를 만드는 1대 1 변환방식이다. 이를 KLT 방식이라 하는데, 이 방식이 가진 단점을 보완한 디프프라이버시(Diff. Privacy) 방법도 종종 사용되고 있다.
이 교수는 “원본 데이터와 비식별 테이터가 1:1로 생성되는 방법은 식별될 수 있다는 가능성 때문에 점점 사용률이 떨어지고 있다”라고 밝히면서 “특히 국내의 경우 개인정보보호법의 강화로 인해 비식별 데이터에서 단 1명이라도 재식별이 될 경우 원본 데이터를 제공한 주체가 형사입건까지 되는 상황이기 때문에 사용이 소극적일 수밖에 없다”라고 덧붙였다.
N대 일 방식은 정확도는 떨어지나 재식별 가능성 없어
현재의 비식별화 방식이 가진 단점을 해결하기 위한 방법으로 이 교수는 ‘MAS 비식별화 방식’을 제시했다. MAS 비식별화 방식은 1:1 형태인 KLT 방식과는 달리, 여러 명의 개인정보들을 추상화하여 한 명의 가상 개인으로 표현하는 N대 1 형태가 특징이다.
이 교수는 “예를 들어 원본 데이터에서 김 씨 성을 가진 사람이 10명이 있을 경우, KLT 방식은 10개의 정보에서 개인을 식별할 수 있는 이름 부분을 삭제하고 성만 남긴 10개의 비식별화 정보들을 생성한다”라고 소개했다.
“그러나 MAS 방식은 김 씨 성만 남긴 오직 하나의 비식별화 정보를 생성하기 때문에 다른 외부 데이터와 결합하더라도 원본 데이터의 김 씨 성을 가진 10명 중에 누구인지를 식별할 수 없다. 따라서 재식별 가능성을 100% 방지할 수 있어서 정보 제공자와 사용자 간의 상호 합의를 보다 쉽게 이끌어낼 수 있다”라고 밝혔다.
N:1 방식의 장점은 이 뿐만이 아니다. 만약 두 집단의 빅데이터를 결합하려 할 때, KLT 방식의 경우는 각각의 으로 비식별화 빅데이터에 개인별 임시키를 부여해야 한다. 아무리 정부가 공인한 전문기관이 이 과정을 수행한다 하더라도 1:1 방식은 데이터 결합에 의한 재식별 가능성이 항상 존재한다는 것이 전문가들의 의견이다.
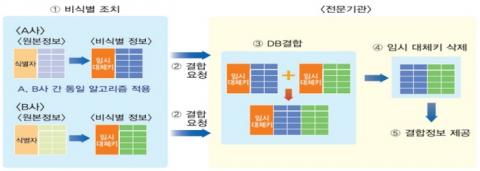
반면에 N:1방식은 개인별 임시키를 생성할 필요가 없다. 데이터를 결합하려는 주체는 데이터 제공자의 비식별화 빅데이터를 직접 전달받아 자신의 비식별화한 빅데이터에 그대로 결합하기만 하면 된다.
이 교수는 “MAS 방식은 개인별 임시키를 생성한 뒤, 전문기관을 통해야 하는 번거로운 과정에서 벗어날 수 있고, 데이터가 유출되더라도 개인정보가 노출될 가능성이 발생하지 않는다”라고 강조했다.
그렇다고 MAS 방식이 KLT 방식에 비해 모든 점이 우수한 것은 아니다. 아무래도 N:1 형태이다 보니 1:1 방식보다 정확도는 떨어질 수밖에 없다.
이 같은 단점을 지적하는 질문에 대해 이 교수는 “비식별화를 통해 빅데이터 산업을 활성화하기 위해서는 다소 정확성이 낮더라도 안정성이 높고 상호 간 합의가 수월한 MAS 방식을 선택하는 것이 시급하다”라고 주장했다.
- 김준래 객원기자
- stimes@naver.com
- 저작권자 2017-04-13 ⓒ ScienceTimes
관련기사
