 뉴스레터
뉴스레터








점점 더 똑똑해지는 외국어 번역 서비스가 생활에 편리를 높이고 있다. 대표적으로 번역 기술을 꾸준히 발전시키고 있는 구글과 네이버의 파파고는 이제 외국어와 모국어 단어를 단순 대체하는 정도를 넘어, 예전과는 비교하기 어려울 정도로 정교해진 까닭이다.
사실 번역은 모국어의 보편문법과는 다른 언어 체계를 학습하고, 언어를 포함한 컨텍스트의 이해를 위해 타 문화와 유동화하는 노력이 수반되어야만 얻을 수 있는 ‘능력’으로, 그래서 ‘인간의 일’로 여겨져 왔다.
지난해 아카데미 시상식에서 봉준호 감독의 영화 <기생충>이 외국어 영화상을 받으면서 ‘번역의 힘’에 대한 관심도가 급증했다. 해외 관객들은 <기생충> 특유의 분위기와 상징에 공감과 환호한 이유를 “자막, 1인치의 장벽(the one-inch tall barrier of subtitles)”을 넘어섰기 때문이라 입을 모았다. 실제로 영화의 대사를 보면 단순히 현지언어로 대체하는데에 그치지 않고, 우리 문화를 현지화하여 언어의 뉘앙스와 극의 분위기를 그대로 전하고 있다. 그리고 이러한 역할은 번역가의 전문적인 통찰과 세심한 능력이라고 평가받았다.
하지만 이 고도의 정신적 작업을 인공지능이 유려하게 처리하는 시대가 시작될 것으로 보인다.
‘흩어진 언어’로 소통하려는 욕망
인류가 각기 다른 언어를 사용하게 된 이유 중 가장 오래된 기록은 <구약성경>에서 찾을 수 있다. 창세기에 등장하는 ‘바벨탑 이야기’는 인간이 하늘에 닿을 수 있다는 교만함으로 바벨탑을 쌓자, 신이 인간의 언어를 서로 알아듣지 못하게 ‘흩었다’, ‘뒤섞었다’라고 기록돼 있다.
이후 다른 언어들을 이해하고, 소통하고자 하는 인간의 욕망을 해소하는 일은 사람의 일이었고, 전문적인 영역이었다.

기계 번역의 역사, 점점 더 정교하게
먼저, 기계번역이 등장하기 전에 국제 공용어 운동이 유럽 일부에서 등장한 바 있지만, 국제 사회의 패권과 밀접하게 연관되어 실현되지는 못했다.
그리고 이후 군사적 목적으로 등장한 기계번역이 현재 번역의 뿌리라고 할 수 있다. 구본권 한겨레 신문 선임기자는 <로봇시대, 인간의 일>에서 “기계번역의 역사는 제2차 세계대전에 뿌리가 닿아있다”라며 기계번역의 역사를 소개한다.
나치 독일의 암호체계인 애니그마를 해독하는 과정에서 축적된 경험이 1950년대 미국의 대학과 연구기관으로 이전됐고, 1954년 미국 조지타운 대학과 IBM에서 러시아어-영어를 대상으로 최초의 기계번역 공개 실험을 시도했다는 것이다.
당시의 번역은 사람을 통한 번역보다 비용은 더 많이 들고, 정확도는 떨어진다는 이유로 연구와 결과에 대한 기대도 주춤한 사이, IBM에서 통계 방식의 접근법으로 시도한 기계번역(SMT: Statistical Machine Translation)이 등장하면서 기계번역 역사에 전기가 마련됐다.
SMT는 대규모의 말뭉치 덩어리에서 단어 간의 정렬을 찾고, 빈도수를 구하여 통계 정보를 학습한 후 그 확률값을 기반으로 번역을 수행하는 방식이다. 즉 입력한 문장의 단어·구 단위로 대체어의 그룹을 나열한 후, 그 그룹에서 확률값이 가장 높은 길을 따라 번역을 완성하는 것. 하지만 초기의 SMT는 단어나 구 단위로 번역이 되기 때문에 자연스럽지 못한 오류를 초래하기도 했다.
물론 데이터가 축적되고, 그 양이 많아지면서 정확도가 높아지면서 SMT가 번역의 대세가 되기도 했지만, 여전히 사람의 언어에 가까운 유려함은 떨어졌다.

인공 신경망 기반 기계번역
이처럼 정밀도가 낮았던 기계번역의 한계를 극복한 것은 인공 신경망 기반의 기계번역(NMT; Neural machine translation)이 등장한 이후다.
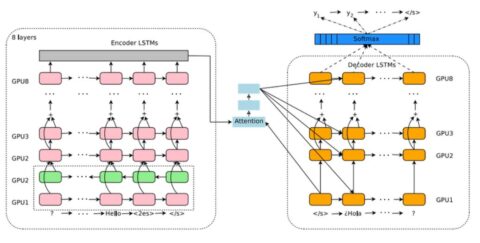
NMT는 입력한 문장을 벡터 형태로 변환한 후, 이를 기반으로 출력하고자 하는 언어를 생성하는 방법이다. 입력한 문장, 즉 인코더(encoder)와 문장의 출력부, 즉 디코더(decoder) 부분이 인공 신경망으로 구성되어 있어서, 이 안에 문장 전체의 방대한 정보가 포함돼 있다. 즉 단어의 의미, 어순, 문장의 구조를 비롯하여 문맥 이해를 위한 모든 컨텍스트가 인공 신경망을 구성하여 스스로 학습한 후 최상의 번역 결과를 내놓는다.
이후, NMT의 부분적 한계를 보완한 RNN(Recurrent Neural Network)이 데이터의 패턴을 인식하는 데 진화된 결과를 나타내면서, 현재 인공 신경망에 기반한 번역 서비스의 기본적인 토대가 마련되었다.
그리고 2016년 구글이 한국어, 영어, 중국어, 프랑스어, 스페인어, 일본어, 터키어 등 총 8개 언어에 대해 인공 신경망 번역을 적용하겠다고 발표한 이후 번역 서비스의 질은 놀라우리만큼 향상됐다.
번역, 언어의 장벽을 허무는 기술로 진화중
『유엔 미래 보고서 2045』에 따르면 인공지능의 도입이 인사담당자, 의사, 택배, 변호사, 기자, 통·번역가, 세무사, 회계사, 텔레마케터 등을 대신하리라 예측한다.
인공지능 기술이 인간이 가진 지각, 학습, 추론, 자연언어 처리 등의 능력을 기계가 충분히, 완벽에 가깝게 수행할 수 있는 수준으로 발전하고 있기 때문이다.
특히 최근 인공지능은 ‘인간처럼 생각하고, 말하기’의 구현까지 가능한 정도가 되었다. 스스로 환경을 인지하여 최적의 답을 찾고, 스스로 수행한 학습을 통해 추론 및 예측을 하며, 문제를 발견하여 판단하고, 해결하는 단계까지 이르렀다. 그렇기 때문에 이러한 진화 방향과 속도에 이미 올라탄 외국어 번역 프로그램이 고도화되고, 번역의 정확도가 높아지는 것은 자명한 사실이다.
앞으로 더 많은 데이터가 축적되고, 또 새로운 데이터가 생성되며, 딥러닝과 인공지능 기술이 발전하는 속도를 고려하면, 언어의 장벽이 사라지는 시대가 올지도 모를 일이다.
- 김현정 객원기자
- vegastar0707@gmail.com
- 저작권자 2021-06-24 ⓒ ScienceTimes
관련기사


