 뉴스레터
뉴스레터








후버댐(Hoover Dam)은 1930년대 대공황으로 무너졌던 미국의 경제를 일으킨 상징과도 같은 존재다. 세계 경제사에 길이 남을 뉴딜(New Deal) 정책을 성공으로 이끈 건설 사업의 핵심 사업장이 바로 후버댐이기 때문이다.
그런데 그로부터 90여 년이 지난 대한민국에서 다시 한번 댐(dam)을 통한 경제 회복 정책이 추진되고 있어 관심이 모아지고 있다. 물론 건설 사업은 아니다. 첨단 디지털 시대에 걸맞게 21세기의 원유라 불리는 데이터를 활용하여 댐을 짓는 사업이다. 바로 데이터 댐(Data Dam)이다.
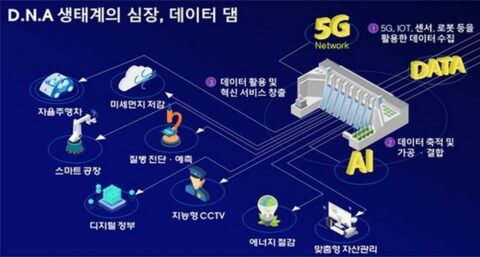
데이터 댐은 디지털 뉴딜 정책의 핵심 사업
데이터 댐은 공공기관이나 민간기업이 데이터를 수집하고, 이를 가공하여 유용한 정보로 재구성한 집합 시스템을 의미한다. 이를 활용하면 더 똑똑한 인공지능(AI)을 개발할 수 있고, 5G 통신과 융합하여 실감 나는 가상현실도 제공할 수 있다.
데이터 댐이라는 개념은 정부가 추진하겠다고 밝힌 디지털 뉴딜 정책에서 나왔다. 디지털 뉴딜 정책은 과거 미국이 대공황을 극복하기 위해 추진했던 뉴딜 정책과 비슷하면서도 다르다. 정책 추진을 통해 대규모 일자리를 만든다는 취지는 비슷하지만, 건설 사업이 아닌 디지털 기술을 통해 일자리를 만드는 것은 다른 점이라 할 수 있다.
다시 말해 뉴딜 정책의 핵심 사업이 후버댐 건설이라면, 디지털 뉴딜의 핵심사업은 데이터 댐 구축이라 할 수 있는 것이다. 물론 물리적인 댐과 디지털 댐은 엄연히 다른 형태이지만, 둘 다 물과 데이터를 가두고 보관한다는 개념은 같다고 볼 수 있다.
하지만 여기서 의문이 생긴다. 도대체 댐을 건설하고 구축하는 것이 어떤 작업이기에 이처럼 경제 회복의 핵심사업으로 꼽히는 것일까. 그 이유를 알려면 우선 댐 공사가 미치는 파급효과에 대해 파악하는 것이 필요하다.
후버댐 건설의 경우 건설 과정 자체만으로도 경기부양 효과가 컸지만, 주변 산업에 미치는 파급효과는 더 컸다고 할 수 있다. 댐에서 확보한 물은 공업용수나 농업용수로 활용했고, 수문 개방을 통해 생성된 수력발전으로 전력을 생산했다. 그렇게 전력이 풍부해지다 보니 지역 경제가 살아나면서 다양한 산업들로 이루어진 생태계가 조성되었다.
데이터 댐도 개념만 놓고 보면 후버댐의 경우와 유사하다. 주요 사업인 데이터를 수집하고 가공하는 작업만으로도 경제 회복에 기여할 수 있지만, 수집한 데이터를 교육과 의료, 국방 분야 등에까지 연계시키면 새로운 비즈니스와 산업을 만들 수 있기 때문이다.
이뿐만이 아니다. 데이터를 수집하고 가공할 때 5G 통신을 이용하면 더 많은 데이터를 더 신속하게 수집하여 활용할 수 있다. 따라서 데이터가 많아질수록 AI가 더 스마트해지기 때문에 데이터와 네트워크, AI를 기반으로 운영되는 데이터 댐을 디지털 뉴딜의 핵심사업이라 부르는 것이다.
데이터 댐 사업의 첫 과제인 AI 학습용 데이터 구축 사업
데이터 댐 사업의 본격적인 추진을 위해 과학기술정보통신부(이하 과기정통부)는 최근 AI 개발에 필수적인 양질의 데이터를 대규모로 구축하고 개방하는 20개의 ‘AI 학습용 데이터 구축 사업’ 과제를 확정했다.
AI 학습용 데이터 구축 사업은 지난 2017년부터 시작된 국책 사업으로서 텍스트와 이미지, 그리고 영상 분야의 AI 서비스 개발을 위해 총 21종, 4650만 건의 기계학습용 데이터를 구축하는 사업이다.
기계학습용 데이터에는 한글과 영어를 번역한 말뭉치와 한국어 음성 등이 포함되어 있다. 이 중에서 말뭉치란 언어 연구를 위해 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 관련 자료를 뜻한다. AI 학습용 데이터 구축 사업을 위해 구축된 기계학습용 데이터는 현재 AI 통합지원 플랫폼인 ‘AI 허브(www.aihub.or.kr)’를 통해 공개 중이다.
선정된 20개 사업 과제를 살펴보면 10개의 지정공모 과제와 10개의 자유공모 과제로 구분되는데, ‘국가적 필요성 또는 산업적 필요성’에 의해 선정됐거나 ‘국민 편의 향상’을 위해 선정된 것으로 나타났다.
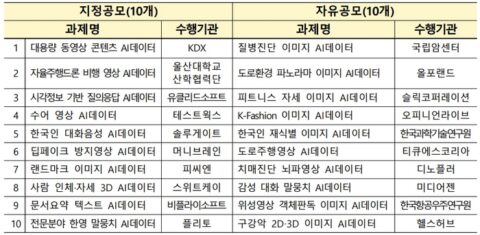
국가적·산업적 필요성에 의해 선정된 과제들은 △사람의 감성과 문맥을 이해할 수 있는 자연어 처리 분야 △자동차와 드론 등 자율주행기술 분야 △음성, 시각, 언어 등 융합 분야 등 활용가치가 높고 데이터 확보 필요성이 시급한 과제들로 선정됐다.
예를 들어 국가적·산업적 필요성에 의해 선정된 과제들 중 지정과제로 선정된 ‘시각 정보 기반 질의응답’ 사업은 생활 이미지와 이미지에 대한 질문을 입력받아 질문에 대한 답을 생성하는 AI 데이터 구축 사업이다. 135만 장의 이미지와 750만 쌍의 한국어 질의응답 등이 포함되어 있다.
반면에 국민 편의 향상을 위해 선정된 과제들은 △질병 진단과 헬스케어 분야 △사람의 얼굴을 악의적으로 변조한 딥페이크 방지 기술 분야 △장애인의 삶을 향상시킬 수 있는 분야 등 국민 생활을 윤택하게 하고 사회적 문제를 해결할 수 있는 과제들로 선정됐다.
국민 편의 향상을 위해 선정된 과제들 중 대표적 사례로는 암조직을 진단할 수 있는 ‘질병 이미지 AI 데이터’ 사업을 들 수 있다. 그중에서도 유방암 질환의 진단을 위한 의료 영상 이미지 AI 데이터가 많이 구축되어 있다.
AI 학습용 데이터 구축 사업이 특히 주목을 받고 있는 이유는 양질의 일자리를 창출할 수 있기 때문이다. AI 학습용 데이터를 수집하고 가공하는 데는 많은 인력이 필요한데, 과기정통부는 누구나 참여하여 데이터를 가공할 수 있는 크라우드소싱 방식으로 인력 부족 문제를 해결하겠다고 밝혔다.
- 김준래 객원기자
- stimes@naver.com
- 저작권자 2020-07-20 ⓒ ScienceTimes
관련기사
